
Zero Trust Architecture - An executive guide
ZTA operates on a fundamental principle - never trust, always verify. Lets understand what it is and how to implement it
ZTA operates on a fundamental principle - never trust, always verify. Lets understand what it is and how to implement it
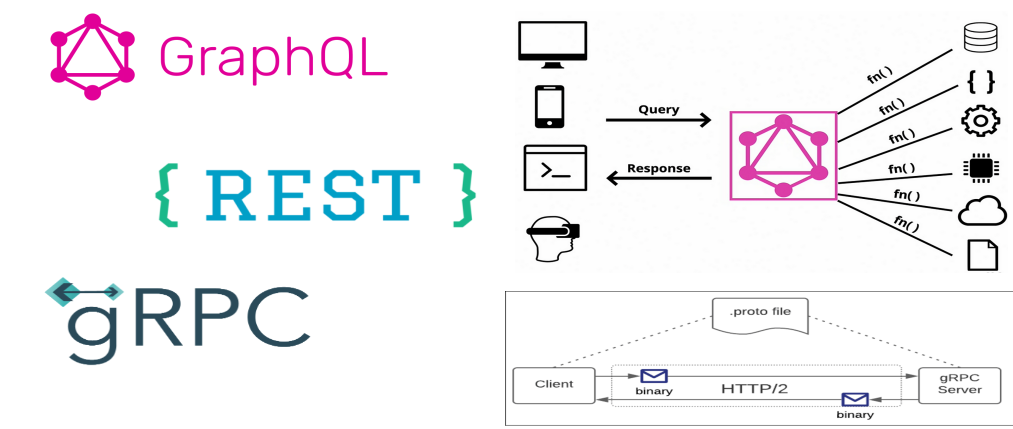
Three technologies stand out as primary choices for developing API’s REST, GraphQL, and gRPC. Understanding what they bring to the table and making sure it aligns with your API design goals is key in developing successful API’s

Dive into gRPC with this tutorial – understand Protocol Buffers, define services, and implement a gRPC server in .NET for fast, efficient communication.
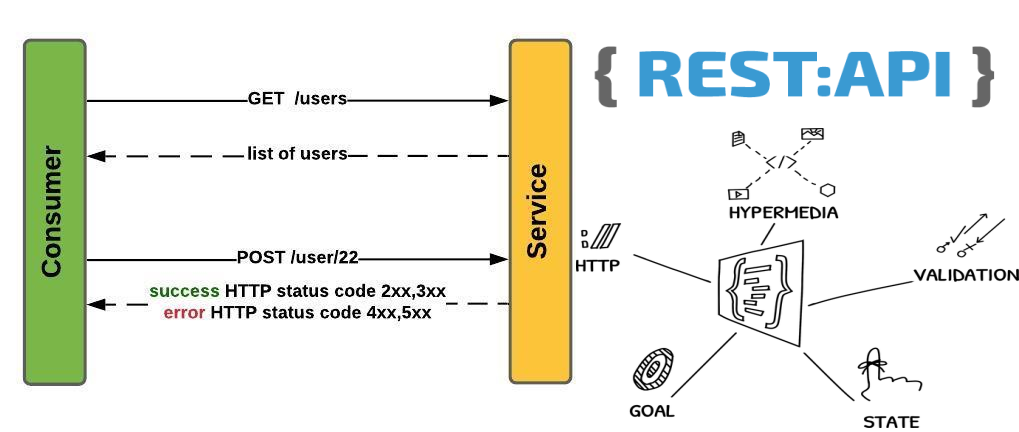
HATEOAS is a key aspect of building Restful web services. It is a key aspect of REST principles

Platform engineering is an emerging discipline that transcends traditional IT roles by bridging software development (Dev), operations (Ops), security (sec), and quality assurance (QA) into a coherent, streamlined workflow

Source Code If you wish to follow along with the code used in this post, you can find it on GitHub here . Kpack - Kubernetes native Buildpacks Kpack is a Kubernetes-native build service that utilizes Cloud Native Buildpacks to transform application source code into OCI compliant container images. Kpack extends Kubernetes by creating new custom resources that implement CNB concepts for image configuration, builders, buildpacks and others. These CRDs allow users to define and manage Kpack resources using the kubernetes native declarative api....
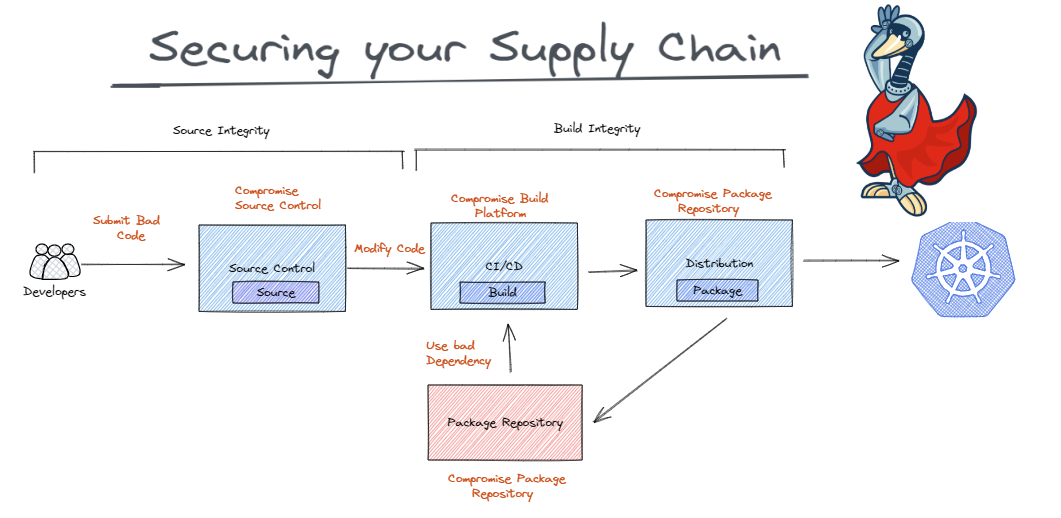
SLSA (Supply chain Levels for Software Artifacts) is a security framework designed to ensure the integrity and security of the software supply chain. It is a set of guidelines and best practices that aim to prevent tampering, improve integrity, and secure packages and infrastructure in software development and deployment.
Introduction One of the key factors in Kubernetes’ success is its ability to facilitate the development and deployment of resilient and highly available applications. This is achieved through a combination of features, including its containerization approach, flexible scaling mechanisms, and robust health check mechanisms. As a container orchestration system it is essential for Kubernetes to keep track of the health of the various nodes, pods and containers in the cluster. Kubernetes uses health checks to monitor the health of applications, containers & pods running in a cluster....
Kappa architecture is a data-processing architecture that is designed to process data in real time. It is a single-layer architecture that uses a streaming processing engine to process data as it is received. This architecture is simpler and more efficient than the Lambda architecture, and it can be implemented at a lower cost.

Lambda architecture is a data processing architecture designed to handle large amounts of data by combining batch processing with real-time stream processing.Lambda architecture provides a way to handle both real-time and batch processing in a single architecture.